Can Fancy Teacher Evaluation Systems End The Achievement Plateau?
We've spent a fortune trying to build perfect evaluation systems. It's not working.

The Rivian R1T truck is an impressive piece of engineering. It’s an all-electric truck with a range of 314 miles with a built-in camping kitchen, automatic highway driving system, and an optional rooftop tent. If you’ve got a spare $70,000 lying around, this is probably the truck for you. Much to the dismay of a good friend of mine, this is not the truck for 99% of drivers.
In public education, many states and districts have spent the last decade trying to build the Rivian of teacher accountability and evaluation — systems so perfectly engineered and full of features that they’re designed to produce accurate and meaningful evaluations of teachers.
Typically, these usually include a series of classroom observations scored on a rubric. Those scores then get factored into a formula that includes a teacher-created student achievement goal, a building level score that gets a “challenge multiplier” for having a large percentage of economically disadvantaged students, and, for certain teachers, some valued-added assessment data. Some even include scores from student and parent surveys. The numbers all get crunched and spit out a score for each individual teacher.
The only problem? They’re just not working, according to a new(ish) paper released by the Annenberg Institute at Brown University. In short, almost a decade of reforms to create these complex and rigorous teacher evaluation systems have produced almost no measurable improvement in reading, math, or high school graduation.
I can guess why. My initial draft of this post had over 30 points, but I can boil them down to this: teachers are mostly doing what is asked of them and evaluating them more and in more complex ways will not change that.
Approaches like improving teacher evaluation are still predicated on education reform 1.0 (maybe -1.0), which purports that those at the school level (teachers and principals) are responsible for The Achievement Plateau. As I’ve written repeatedly, this is akin to holding the chefs and managers to account for the widespread failures of a chain restaurant. We can double down on more complex and more frequent evaluations of the line chefs at The Cheesecake Factory — or we can just give them better recipes, better ingredients, and hire more staff.
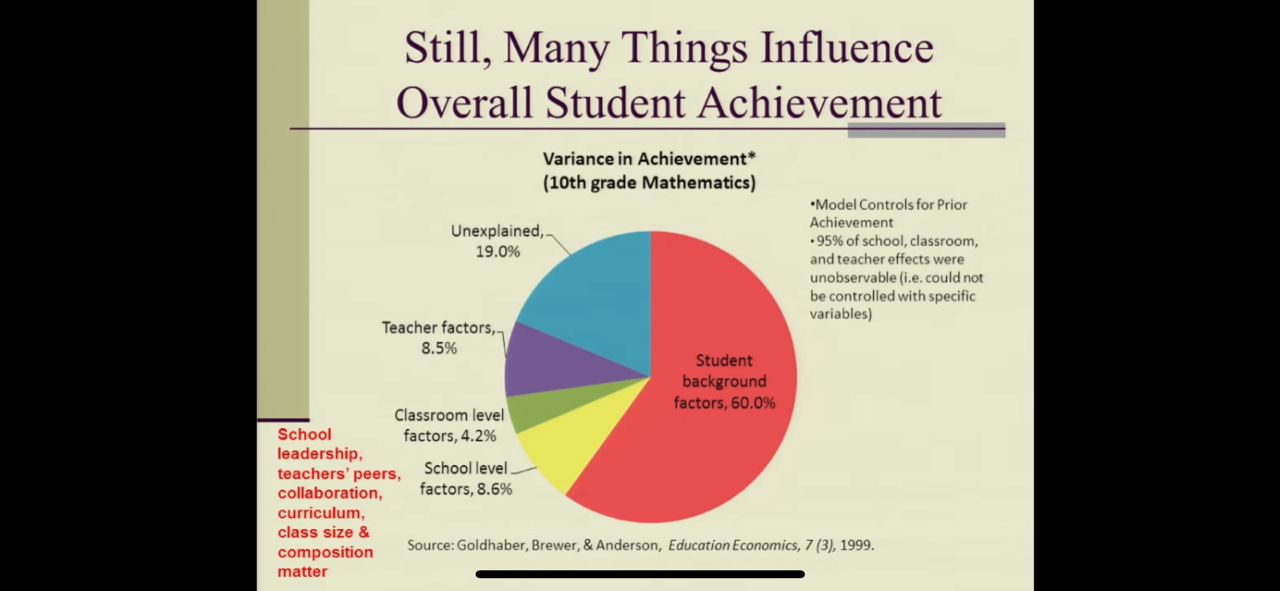
Beyond that, as this lovely chart from this Linda Darling-Hammond talk suggests, teachers don’t account for a large percentage in the variance in student achievement. Schools and districts collectively can have a strong impact, but individual teachers — not so much. (I should note that Darling-Hammond discusses many components that should be included in evaluation systems, and I would disagree with her on that.)

That’s not to say we shouldn’t help them get better — educating at-risk students is challenging work and every incremental gain matters.
But we should be more thoughtful about the rate of return on our investments in reforms. These teacher evaluation reforms cost somewhere between $15-20 billion dollars. That’s a lot of cash for very little return on taxpayers’ investment.
Why are they so costly? Evaluation systems require rubrics (that are paid for) that require regular training for teachers and principals, software systems (to capture the scores from the rubrics) that also require regular adult training, complex data systems at state and local levels to analyze student achievement data and generate a teacher rating — and training on that data and how it’s computed. The maintenance on all those components is also astronomical, just like the maintenance on a vehicle with a built-in camping kitchen.
Some of you might say, “But wait! The DC Public Schools’ system is perfect — it works really well! Matthew Ylgesias even said so right here on Substack!” Yes, there is evidence (even in the Ed Working Paper cited above) that DC’s IMPACT system is slightly improving student achievement and helping exit the tiny, tiny number (just 1% of the workforce) of ineffective teachers. But I’m still unconvinced it’s the right approach.
First, Yglesias admits in the post that out-of-school factors still dominate student achievement. That leaves me asking this question: is this evaluation system the most effective investment we could make in improving outcomes for students?
I’ve also read reports about racial bias and the current chancellor admits the system need to be improved. They’ll likely try to build the Rivian of teacher evaluation systems—replete with camping kitchen and more numbers to get a “clearer” picture of teacher practice. But we could probably do just fine with the Toyota Tacoma of teacher evaluation. More on that next week.
Thanks for reading. Have a great week.